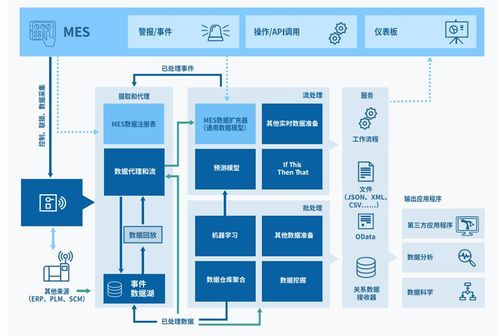
随着工业4.0和智能制造的深入发展,制造执行系统(MES)作为连接企业计划层与控制层的关键枢纽,其架构正经历着深刻的变革。下一代MES系统不仅需要更高的实时性、灵活性和可扩展性,其数据处理与存储支持服务更是核心竞争力的体现。本文旨在分析下一代MES系统在数据处理与存储层面的架构趋势,并提供关键的选型参考。
一、 下一代MES系统数据处理与存储的架构特点
1. 云边协同与混合部署:
下一代MES系统不再局限于单一的本地部署。核心的、对实时性要求相对较低的宏观数据(如生产计划、质量报告、设备OEE)可部署于企业私有云或行业公有云,以获得强大的弹性计算和存储能力。而在车间现场,边缘计算节点负责处理高并发的实时数据(如传感器读数、PLC状态、视觉检测结果),进行本地化即时分析和响应,再将聚合后的结果上传至云端。这种架构降低了网络延迟和带宽压力,并提升了系统的整体韧性。
2. 微服务与数据中台化:
传统单体式MES的数据处理逻辑紧耦合,难以扩展和维护。下一代架构普遍采用微服务设计,将数据采集、实时处理、历史存储、分析计算等能力拆分为独立的、可独立部署和伸缩的服务。通过构建面向制造域的“数据中台”,将来自设备、物料、人员、工艺等不同源头的数据进行标准化、资产化管理,形成统一的数据服务层,为上层各类应用(如生产监控、质量追溯、绩效分析)提供一致、可靠的数据供给。
3. 多模数据存储与实时流处理:
制造场景产生的数据是典型的多模态数据:时序数据(设备传感器)、关系数据(BOM、工单)、文档数据(SOP、图纸)、时空数据(物料位置)、非结构化数据(图像、日志)。因此,下一代MES的存储架构必然是混合的:
- 时序数据库(TSDB):如 InfluxDB、TDengine,用于高效存储和查询海量时间序列的设备和工艺参数。
- 关系型数据库(RDBMS):如 PostgreSQL,用于存储核心的业务实体和关系数据,保证事务一致性。
- 文档/宽列数据库:如 MongoDB、Cassandra,用于存储灵活的、半结构化的数据,如工艺配方、设备档案。
* 对象存储:如 MinIO、AWS S3,用于存储大量的非结构化文件,如检测图片、视频录像。
流处理框架(如 Apache Kafka + Apache Flink)成为标配,实现对数据流的实时计算、复杂事件处理(CEP)和即时告警。
4. 数据智能与AI原生:
数据处理的目的从“记录与展示”升级为“预测与优化”。架构需原生集成机器学习平台和AI服务,能够方便地对历史数据进行训练,并将模型部署到边缘或云端进行实时推理,实现诸如预测性维护、工艺参数优化、质量缺陷自动分类等智能应用。
二、 数据处理与存储支持服务选型关键考量
在选择具体的技术栈和服务时,需从业务、技术、成本等多个维度进行综合评估:
- 业务需求匹配度:
- 数据规模与速度:评估每秒产生的数据点数(Data Points Per Second)、数据保存期限要求,这决定了TSDB和流处理组件的选型。
- 实时性要求:区分毫秒级响应的控制指令下发和秒/分钟级的分析报表,决定边缘计算与云端计算的职责划分。
- 查询与分析模式:明确是点查询为主,还是复杂的聚合分析、关联查询居多,影响数据库的索引和表结构设计。
- 技术成熟度与生态:
- 社区活跃度与商业支持:优先选择有活跃开源社区或可靠商业公司背书的方案,确保长期的技术演进和问题解决渠道。
- 与现有系统集成:评估与现有ERP、PLM、SCADA及各类工业协议(OPC UA, MQTT等)集成的便捷性。
- 开发与运维复杂度:考虑团队技术栈,选择学习曲线平缓、运维工具链完善的组件。容器化(Docker/Kubernetes)部署能力是重要加分项。
- 性能、可靠性与安全性:
- 读写性能与可扩展性:通过PoC验证在高并发读写场景下的性能表现,以及水平扩展的能力。
- 高可用与容灾:确保数据库集群、消息队列具备主从复制、分片等机制,保障服务不间断。
- 数据安全:考察数据传输加密、存储加密、细粒度访问控制(RBAC)以及符合行业安全规范(如等保2.0)的能力。
- 总拥有成本(TCO):
- 许可与云服务费用:对比开源方案与商业软件许可费,或不同云厂商的托管服务(如 Amazon Timestream vs. 自建 InfluxDB集群)的长期成本。
- 硬件与运维成本:估算所需的服务器、存储资源以及专职运维人力的投入。
三、 典型技术栈选型参考示例
- 边缘数据采集与轻量处理:Node-RED / 轻量级Java/Python应用 + MQTT Broker(EMQX, HiveMQ) + 边缘时序数据库(TDengine, InfluxDB OSS)。
- 云端核心数据中台:微服务框架(Spring Cloud, Go Micro) + 消息总线(Apache Kafka) + 流处理(Apache Flink) + 混合存储(PostgreSQL for业务数据,InfluxDB Cloud/TDengine Cloud for时序数据,MinIO for对象存储)。
- 数据可视化与分析:Grafana(实时监控仪表盘) + 主流BI工具(如 Tableau, Superset)或内置分析模块。
- 部署与运维:基于Kubernetes的容器化编排,采用 Helm Chart 进行应用管理。
###
下一代MES系统的数据处理与存储架构,本质上是构建一个支撑智能制造的数据基石。选型没有“银弹”,关键在于深刻理解自身制造业务的数据特征与未来需求,采用“云边协同、微服务解耦、多模存储、流批一体”的现代架构思想,并选择在性能、成本、生态间取得最佳平衡的技术组件。一个灵活、健壮且面向未来的数据层,将是MES系统驱动制造数字化转型、释放数据价值的强大引擎。