在大数据时代,高效、可靠的数据处理和流转是许多企业面临的挑战。Apache NiFi(Niagara Files)作为一个强大的可视化数据流编排与调度框架,凭借其面向流程的设计理念和丰富的功能,成为了处理数据移动、转换和分发的热门选择。本文将深入解析NiFi在数据处理和存储支持方面的核心能力。
一、NiFi的核心架构与流程导向
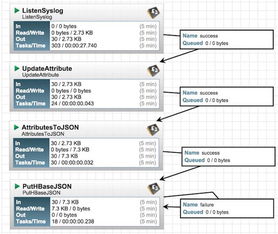
NiFi的核心设计思想是“数据流即流程”。它将复杂的数据处理任务抽象为可视化的流程图,其中每个节点代表一个处理器(Processor),连线代表数据流向。这种设计让数据工程师能够直观地设计、监控和管理数据管道,而无需编写大量底层代码。NiFi架构包含以下关键组件:
- Flow Controller:调度与协调数据流的核心引擎。
- Processor:执行具体操作(如读取、转换、写入)的功能单元。
- Connection:处理器间的缓冲队列,确保数据可靠传递。
- FlowFile Repository:记录FlowFile(数据单元)状态,保证可恢复性。
- Content Repository:存储FlowFile的实际内容,支持版本控制。
- Provenance Repository:跟踪数据血缘,提供完整的审计追踪。
二、数据处理能力:丰富的处理器生态
NiFi的强大之处在于其庞大的处理器库,支持从简单传输到复杂转换的各类操作。主要类别包括:
- 数据摄取与输出:支持从多种源头获取数据(如Kafka、HTTP、数据库、文件系统),并能输出到HDFS、S3、Kafka、Elasticsearch等目标系统。
- 数据转换:内置处理器支持格式转换(JSON/XML/CSV等)、内容提取(正则表达式、XPath)、加密解密、压缩解压等。
- 路由与过滤:可根据属性、内容将数据流动态路由到不同分支,实现条件分流。
- 系统集成:提供HTTP监听/调用、JMS消息处理、SQL执行等处理器,便于与外部系统交互。
- 自定义扩展:用户可通过开发自定义处理器(Java)来满足特定需求,灵活扩展功能。
三、存储支持服务:可靠性与可扩展性
NiFi在数据存储层面提供了多层次支持,确保数据在流动过程中的持久化和高可用性:
- 数据持久化机制:
- FlowFile Repository:使用嵌入式数据库(如H2)或外部数据库(如PostgreSQL)记录FlowFile元数据,重启后可恢复流程状态。
- Content Repository:默认将数据内容存储在本地磁盘,并可配置多块磁盘提升吞吐量;也支持外部存储如HDFS或云存储。
- Provenance Repository:存储详细的数据血缘信息,支持快速查询数据历史,满足合规要求。
- 高可用与集群模式:NiFi支持集群部署,多个节点共享同一数据流定义,通过ZooKeeper协调,实现负载均衡和故障自动转移。内容仓库可配置为共享存储(如NAS或HDFS),确保集群内数据一致性。
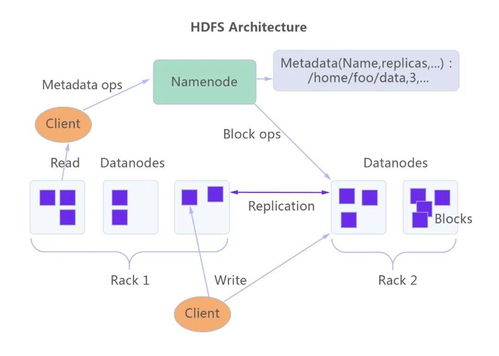
- 与大数据存储系统集成:NiFi原生支持将数据写入HDFS、HBase、Cassandra、MongoDB、Amazon S3等主流存储系统,并可通过处理器优化写入性能(如合并小文件、分区存储)。
四、典型应用场景
- 数据湖/仓库注入:从分散的源系统实时采集日志、事务数据,经过清洗转换后加载到HDFS或云存储,构建数据湖。
- 实时流处理预处理:作为Kafka等消息队列的前置环节,进行数据格式化、过滤和丰富,再推送至流处理引擎(如Flink、Spark Streaming)。
- 系统间数据同步:在企业内部不同数据库、API服务间可靠地同步数据,保证数据一致性。
- 物联网数据采集:从传感器、设备网关接收数据,进行初步聚合后存储到时序数据库或大数据平台。
五、优势与考量
优势:
- 可视化低代码:通过拖拽即可构建复杂流程,降低开发门槛。
- 高可靠与容错:内置背压机制、数据持久化和事务支持,确保数据零丢失。
- 细粒度安全控制:支持基于角色的访问控制(RBAC)、数据加密和SSL/TLS通信。
- 强大监控能力:实时显示数据吞吐量、队列状态,便于性能调优和故障排查。
考量点:
- 对于极低延迟(毫秒级)场景,NiFi的流程调度可能引入一定开销。
- 大规模集群部署需要仔细规划存储和网络配置。
- 复杂业务逻辑仍需配合外部计算框架(如Spark)完成。
###
Apache NiFi通过将数据处理任务流程化、可视化,显著提升了数据管道的开发效率和运维可靠性。它在数据摄取、转换和分发环节表现出色,并与各类存储系统深度集成,成为大数据生态中连接数据源与存储计算平台的“智能数据总线”。无论是构建实时数据流水线,还是实现系统间可靠数据同步,NiFi都是一个值得考虑的成熟解决方案。通过合理利用其处理器生态和集群能力,企业可以构建出既灵活又稳健的数据处理体系。