在人工智能(AI)技术日新月异的今天,模型复杂度的提升、训练数据量的激增以及对实时推理的苛刻要求,共同指向了一个核心命题:传统的、孤立的、静态的数据处理与存储模式已难以为继。AI的下一步突破性发展,将愈发依赖于一个更智能、更高效、更协同的底层支撑体系。而“数据编排”,作为数据处理与存储领域的关键演进方向,正扮演着这一支撑体系的核心角色,成为驱动AI迈向新高度的关键引擎。
一、AI演进对数据处理与存储提出新挑战
当前,AI模型的训练与部署正面临前所未有的数据挑战:
- 数据规模与多样性爆炸:从TB级到PB级甚至EB级的数据集成为常态,数据形态也从单一的结构化数据,扩展到涵盖图像、视频、文本、语音、传感器信号等多模态数据。如何高效地采集、整合、清洗如此海量且异构的数据,是首要难题。
- 处理流程的复杂性与动态性:一个完整的AI数据流水线包括数据接入、预处理、标注、特征工程、模型训练、验证、部署及持续的监控与再训练。各环节工具链不一,资源需求各异,且需要根据模型迭代动态调整。如何无缝协调这一复杂流程,避免“数据孤岛”和流程断点,是提升研发效率的关键。
- 对性能与成本的极致要求:训练大规模模型(如大语言模型)需要极高的I/O吞吐量和低延迟的数据访问,以避免昂贵的计算资源(如GPU集群)闲置。海量数据的长期保存、归档与合规管理也带来了巨大的存储成本压力。
- 数据治理与安全的复杂性:在数据流动的每一个环节,都需要确保数据的质量、一致性、可追溯性,并严格遵守隐私保护(如GDPR)和数据安全法规。
传统的数据管理方式,往往依赖于手动脚本、分散的工具和静态的存储配置,难以应对上述挑战,导致数据科学家和工程师将大量时间耗费在数据搬运和基础设施调试上,而非核心的算法与模型创新。
二、数据编排:定义与核心价值
数据编排(Data Orchestration)是一种新兴的技术理念与平台能力。它通过一个统一的控制平面,对跨多种环境(本地、云、边缘)的数据、计算资源和工作流进行智能化的协调、调度与优化管理。其核心目标在于让数据在正确的时间、以正确的形式、高效且安全地流向需要它的计算任务。
在支持AI发展的语境下,数据编排的价值具体体现在:
- 自动化与智能化的数据流水线:数据编排平台(如Kubernetes上的KubeFlow、Airflow、Prefect等)可以定义、调度和监控复杂的多步骤AI工作流。它能自动触发数据预处理任务,将处理好的数据直接输送给训练任务,并在训练完成后自动启动模型评估与部署,实现端到端的自动化,极大提升研发运营(MLOps)效率。
- 统一的数据虚拟化与访问层:通过数据编排,可以构建一个逻辑上统一的“数据湖”或“数据网格”视图,物理上分散在对象存储、数据库、数据仓库中的多源数据,能够被AI工作流以标准接口透明地访问。这消除了数据复制和迁移的麻烦,保证了“单一数据源”的真实性。
- 性能优化与成本控制:智能编排器可以根据任务优先级和数据局部性原理,动态地将计算任务调度到离数据最近的存储节点,或者将热数据缓存到高速存储(如SSD)中,从而最大化I/O性能,减少训练时间。它还能基于策略自动将冷数据转移到成本更低的存储介质,实现存储成本的整体优化。
- 增强的数据治理与安全:编排平台可以集成数据血缘追踪、质量监控和访问策略管理。所有数据的流动、转换和使用都有迹可循,并能强制执行基于角色的访问控制和数据脱敏策略,为合规AI奠定基础。
三、数据处理与存储服务的协同演进
数据编排并非取代现有的数据处理(如Spark、Flink)和存储服务(如对象存储、并行文件系统),而是作为“粘合剂”和“大脑”,使其协同工作,发挥更大效能:
- 数据处理服务:正朝着“无服务器化”和容器化发展。数据编排平台可以将一个数据处理任务(如特征转换)封装为一个容器化的微服务,按需弹性调用,并按实际使用量计费,实现极致的资源利用率。
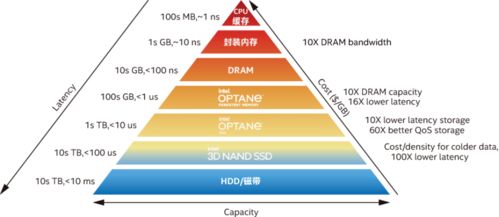
- 数据存储服务:正从单一介质向分层、智能的存储体系演进。通过数据编排策略,热数据可置于高性能全闪存阵列,温数据置于大容量硬盘,冷数据则归档至磁带或云上的冰川存储。整个分层过程对AI应用透明,实现性能与成本的最佳平衡。
四、展望:数据编排驱动AI未来
数据编排与AI的结合将更加深入:
- AI for Data Orchestration:利用机器学习算法来优化编排策略本身,例如预测数据访问模式以进行智能预取和缓存,或自动诊断数据流水线中的瓶颈并给出优化建议。
- 面向生成式AI与大规模基础模型:生成式AI需要处理超大规模的非结构化数据集,并进行持续的增量学习和微调。数据编排将成为管理这些持续流动、版本化的数据和模型产物的核心基础设施。
- 边缘-云协同AI:在物联网和边缘计算场景中,数据编排将负责协调边缘设备的数据过滤、初步处理与云中心的大规模模型训练和更新,实现高效的数据闭环。
###
数据不再是静态的资产,而是流动的生产要素。数据编排,通过其智能化的协调与管理能力,将原本割裂的数据处理与存储服务整合为一条高效、弹性、可靠的“数据供应链”,直接服务于AI模型的“智能生产线”。它解决了AI规模化应用中的核心数据瓶颈,释放了数据潜能。因此,投资和构建先进的数据编排能力,已不仅仅是IT基础设施的升级,更是企业赢得AI时代竞争优势的战略基石。AI的下一步发展,必将在高度编排化的数据沃土上,结出更丰硕的果实。